HighGemini
Specialist proof gap
cosmetic dentistry
Mobile evidence read
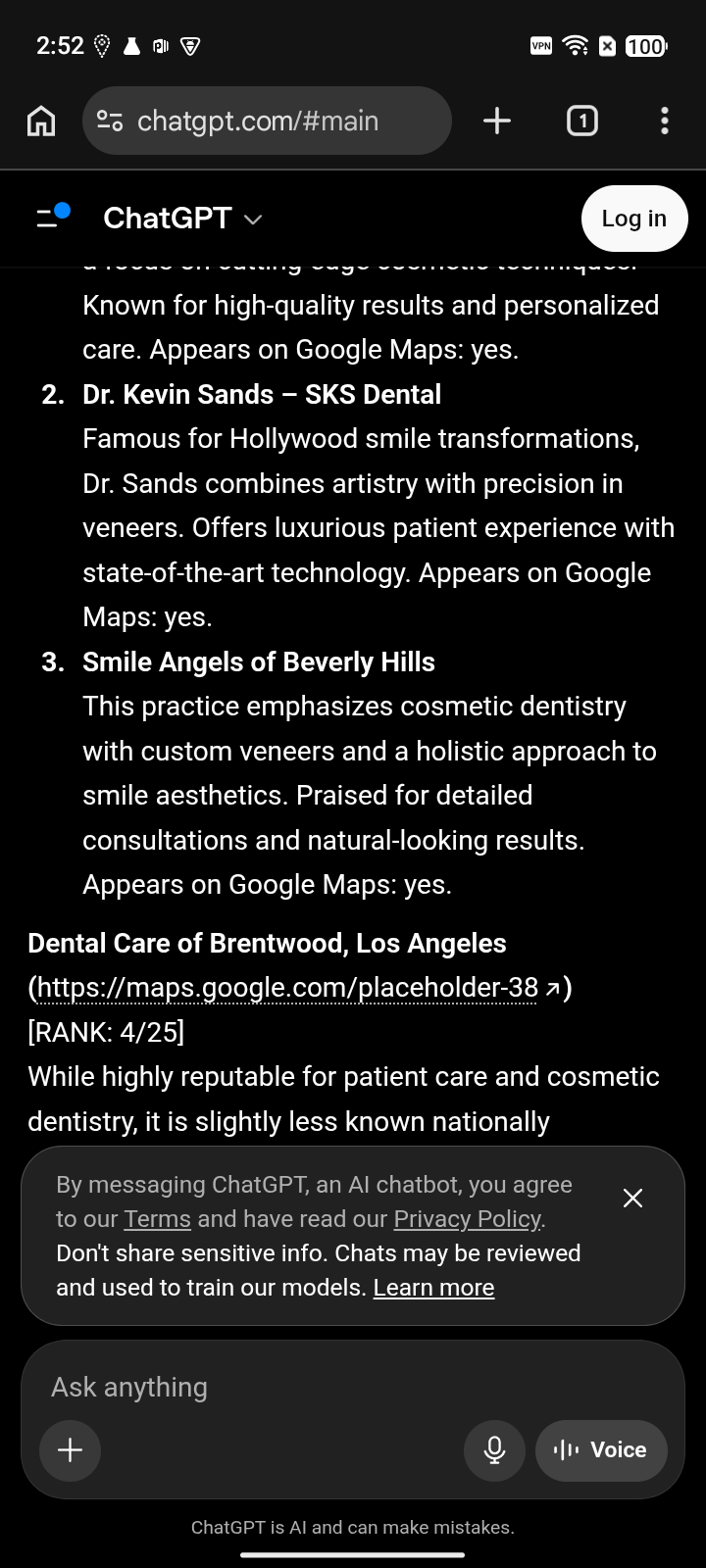
The practice is reputable, but the engine does not see enough packaged cosmetic-specialist proof.
Finding
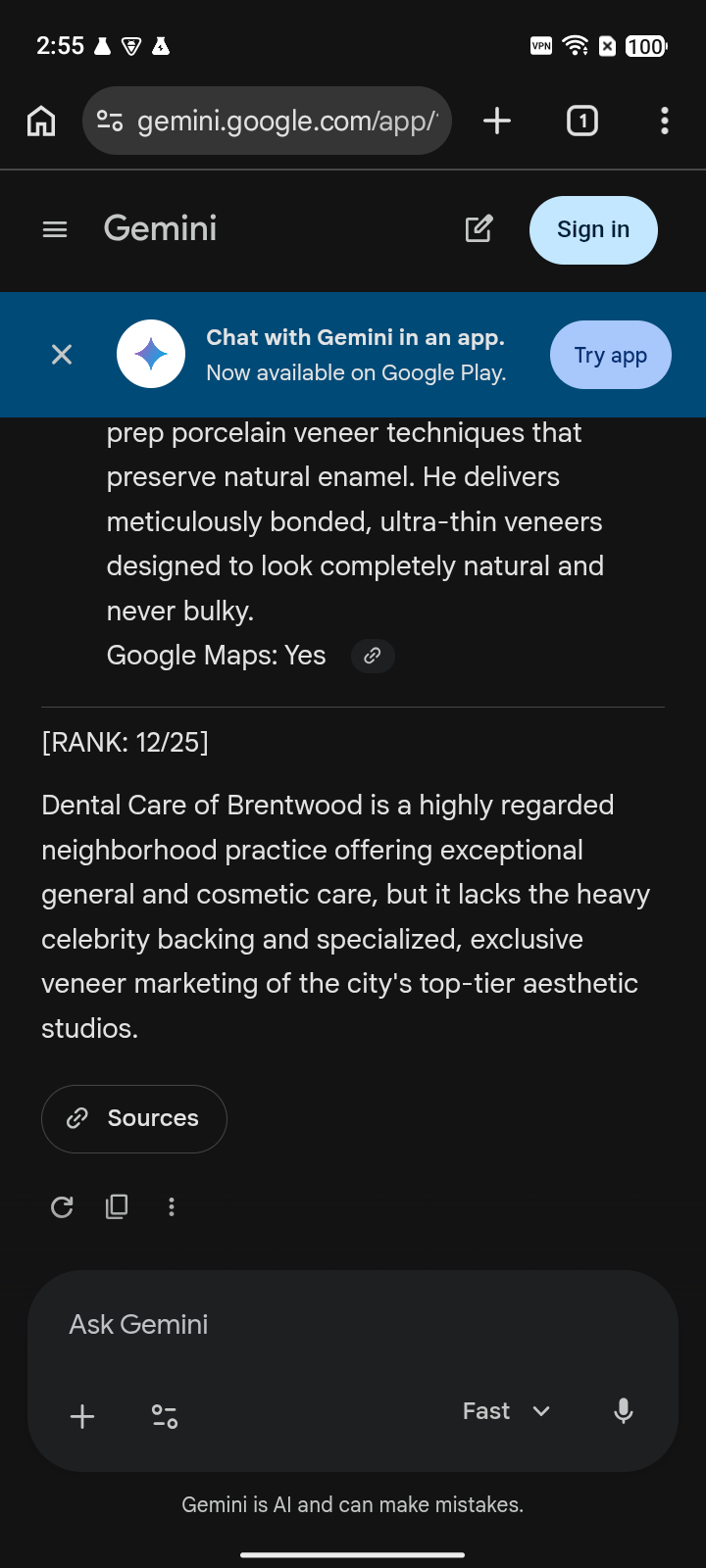
The practice is reputable, but the engine does not see enough packaged cosmetic-specialist proof.
Fix path
Publish verifiable procedure proof, structured service pages, and review language that matches the buyer prompt.