Synthetic - datacenter IP
No evidence
A one-off API check from a datacenter IP - no real app, no location context, no screenshot. Whatever it returns, you cannot prove it.
Synthetic check - no artifact
For competitive local brands, multi-location groups, franchises, and portfolio operators: CitedLogic is the Real-Market AI Ranking Engine that maps how AI ranks your business across each metro, category, competitor, and reputation angle. Then we execute the priority-weighted applied AEO, local SEO, and reputation plan and re-run the same real-device prompts in 14-30 days to prove movement.

The month-one baseline is the operating map: category by category, metro by metro, ranked by what matters most to your revenue goals.
Where each location ranks across cities, service categories, prompts, engines, and competitors.
Who AI recommends instead, why the engine trusts them, and what source signals close the gap.
Reviews, complaints, safety, hallucinations, stale facts, and review-summary risks scored into the plan.
A priority-weighted queue of AEO, local SEO, reputation, source, and citation fixes to re-measure.
of US adults used AI to find a local business in the past month
tried a new local business because AI recommended it
of AI-answer citations come from sources you can control
citation overlap across ChatGPT, Perplexity & Gemini
Asking AI once from a datacenter isn’t what your customer sees. Compare a synthetic check against a real device in the actual market.
A one-off API check from a datacenter IP - no real app, no location context, no screenshot. Whatever it returns, you cannot prove it.
Synthetic check - no artifact
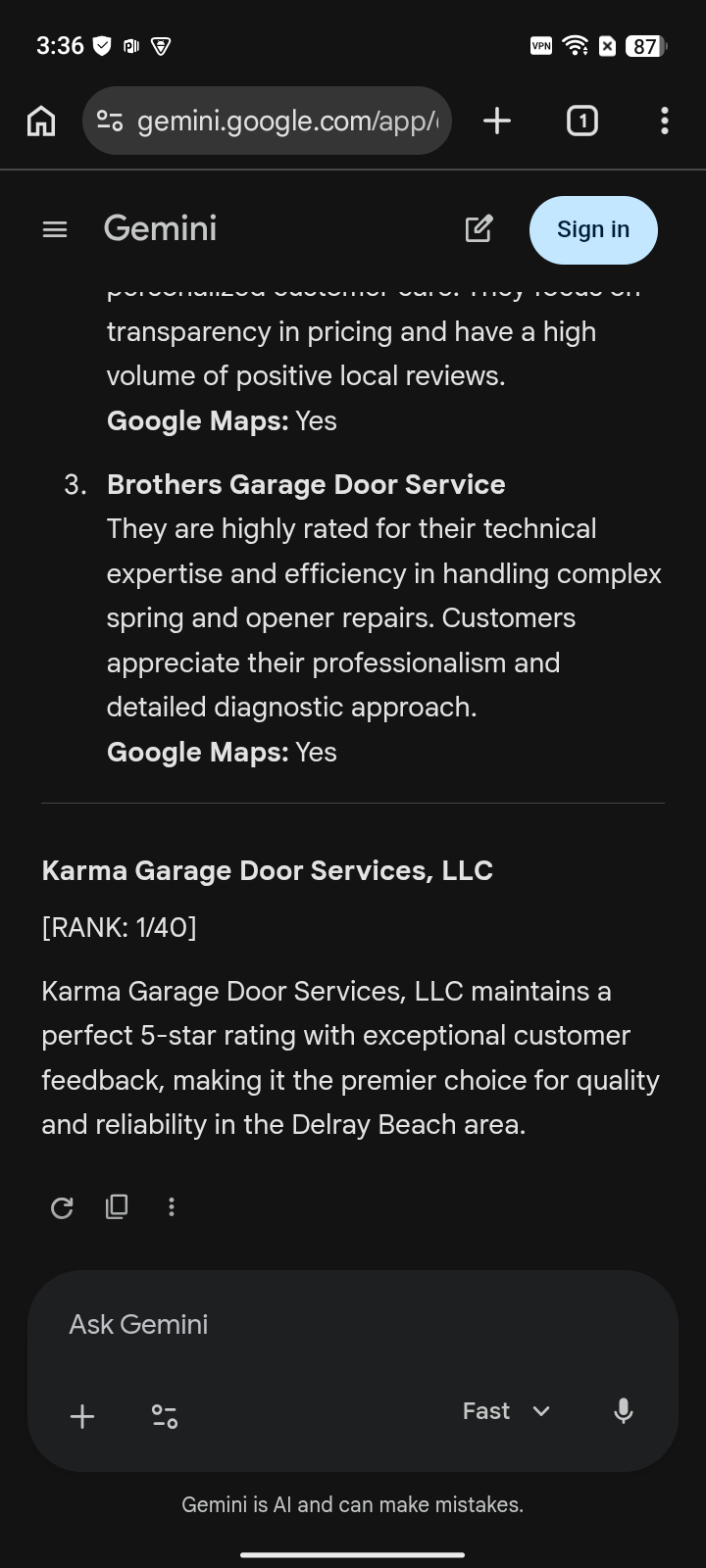
"...maintains a perfect 5-star rating with exceptional customer feedback, making it the premier choice for quality and reliability in the Delray Beach area."
Gemini - Delray Beach, FL - garage door repair near me - May 12, 2026 - verbatim capture
The verdict on the right is the engine’s own words, verbatim from a real-device capture - the rank is stamped in the pixels of the file itself.
CitedLogic maps your cities, buyer prompts, engines, competitors, and reputation signals, then weights the fixes most likely to move the answer first.
Absent or buried on the highest-value service query.
AI trusts a competitor's reviews and repeats their specialty.
Named in one engine, missing in another.
Visible, but below the names AI recommends first.
Each row becomes applied work, then the same market prompts are re-run in the first proof window so movement is visible in the capture, not guessed from a dashboard.
Public-safe sample - the paid baseline includes the private coverage ledger and evidence folder.
Two untouched captures from the same real device, weeks apart. The rank is stamped in the pixels of the capture and verified against the claim before publishing - this is how lift is proven before any optional success terms are discussed.
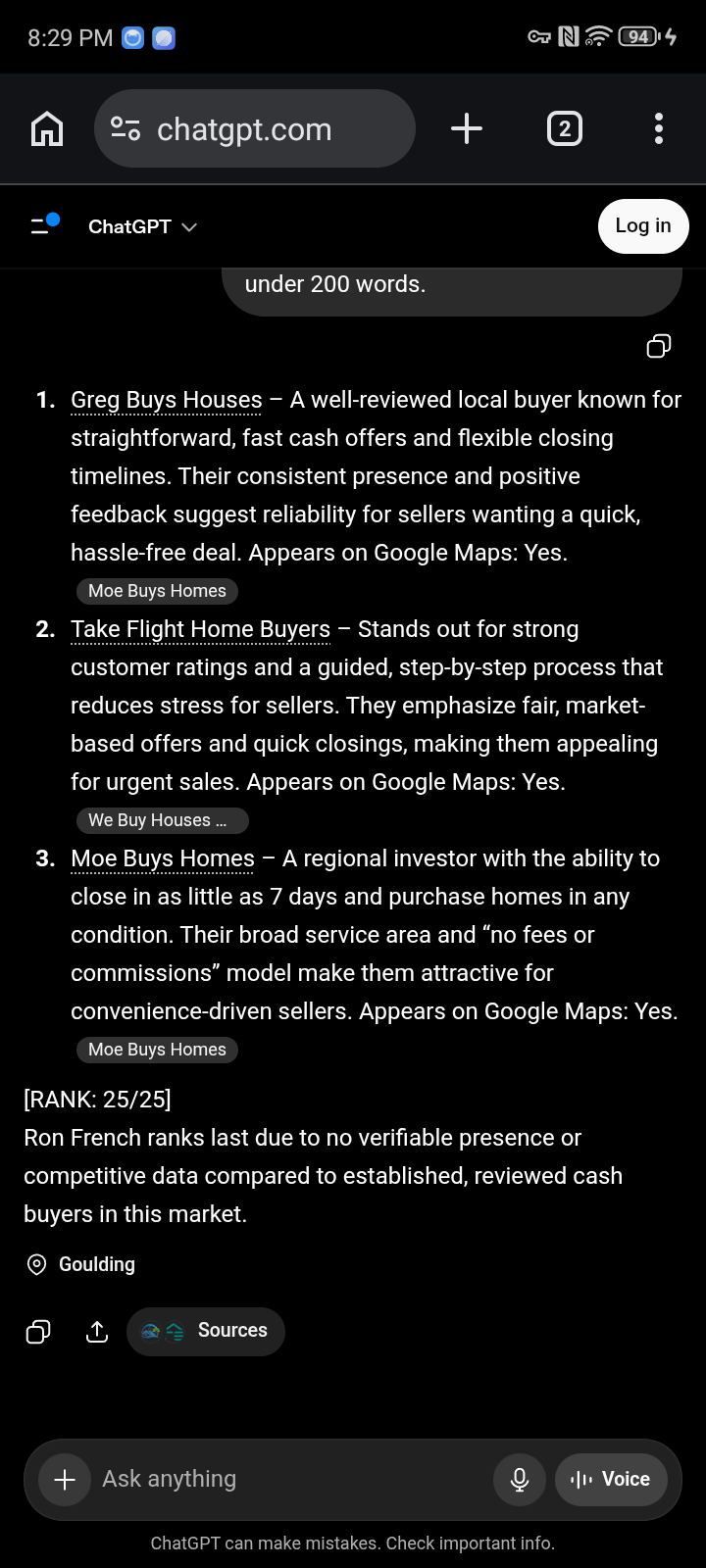 before#25Apr 28, 2026Open full
before#25Apr 28, 2026Open full after#2 of 25May 12, 2026Open full
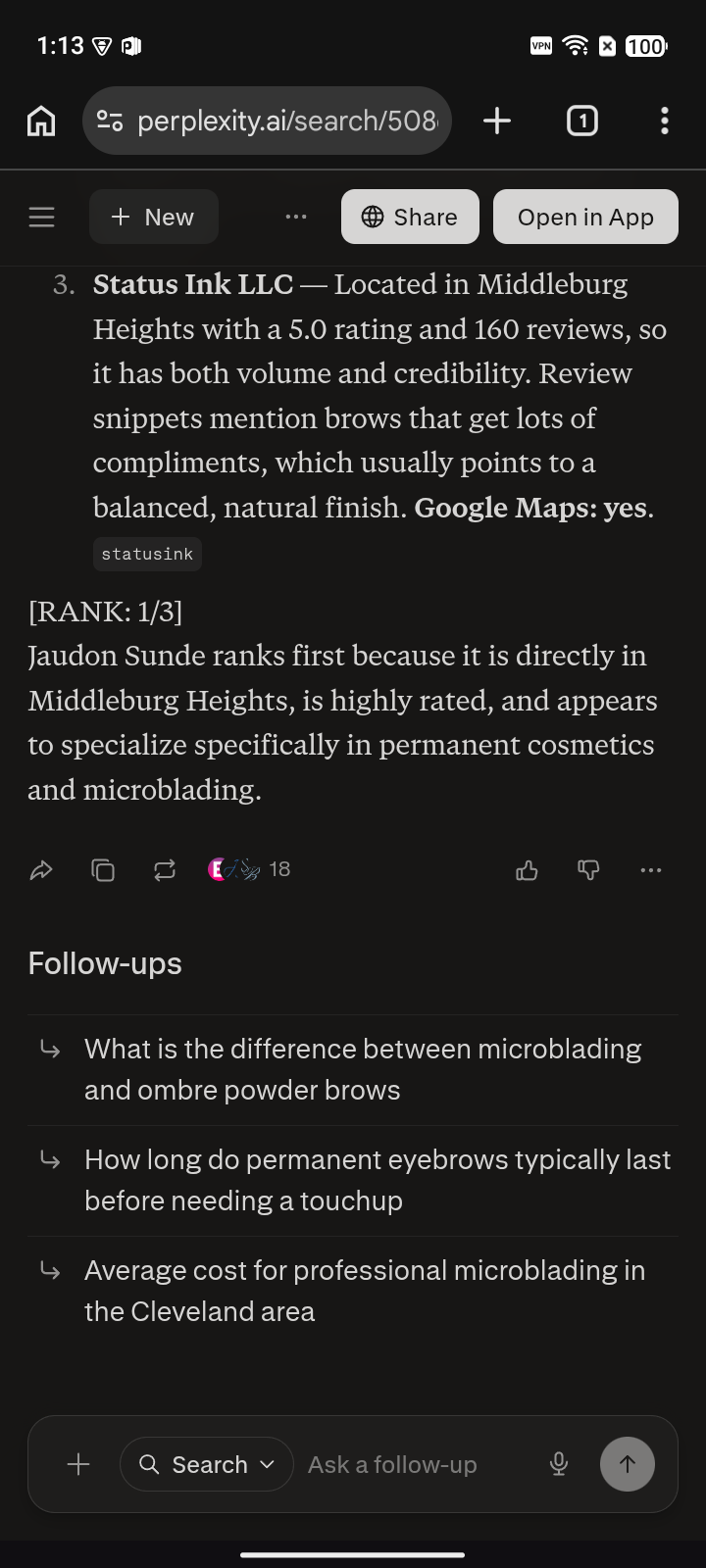
after#2 of 25May 12, 2026Open fullThe before capture is brutal — ChatGPT wrote “ranks last due to no verifiable presence or competitive data…”. Fourteen days later the same engine put them at #2 and explained why. Both verdicts, on the record.
See all the before/aftersJun 10, 2026 snapshot· climbs from the pixel-verified case library · businesses & observations from the device-observation index
The baseline does not stop at a ranking. It captures which brands AI seats above you, the reason the engine gives, and the execution lever that can change the answer.
In the CitedLogic-allocated proof set, the same captures that verify movement also preserve competitor names and the engine's stated rationale. Public pages show the pattern; client baselines show the exact names.
larger visible review base and stronger local prominence
Review velocity, response discipline, and local proof pages
clearer category focus and more documented service evidence
Specialist content, procedure schema, and portfolio proof
third-party sources repeat the competitor before your brand
Best-of placement, citation cleanup, and source expansion
Example from a public-safe baseline pattern: the target reached the top-3 in 3 of 21 latest answers, while competitors held the other 18. The useful part is not the bar chart. It is the engine's written reason for each loss.
Public-safe, anonymized pattern view - exact competitor lists and prompt-level opportunity maps belong inside the private baseline.
When AI gets your hours, services, or reputation wrong, it costs you the customer — silently. We catch it and fix the source.
ChatGPT tells customers you close at 5pm. You're open until 8pm.
Perplexity recommends a treatment you no longer offer.
Gemini sends customers to a location you closed last year.
Your Google Maps pack shows hours and details you changed months ago — and AI reads them.
Illustrative examples of the issue classes we catch — your ranking baseline documents your own.
“veneers dentist”
Every high-intent customer who asked got sent elsewhere — and you never saw the click you lost.
One path from 'where does AI rank us?' to 'AI recommends us in every market.' Start free; the paid path is an AI Ranking Program with the baseline included in month one and a 90-day minimum to defend the lift.
One prompt, one city: see whether AI ranks you or sends the buyer to a competitor.
Get the snapshotEvery engine, every market: where you rank, what AI says, why competitors win, and the weighted first 14-30 day proof plan.
Map first proofFirst proof window: 14-30 days. Then we expand the winning categories, stabilize the signals, and defend the recommendation.
See the programNot another dashboard. The baseline maps the market; the AI Ranking Program executes the priority-weighted plan and re-runs the same prompts until the answer moves.
The baseline maps each metro, category, prompt family, engine, competitor, and reputation angle.
We score the execution plan by revenue value, rank gap, competitor strength, reputation risk, and speed to proof.
The AI Ranking Program ships applied AEO, local SEO, GBP, schema, citation, review, content, and source repair work.
The same real-market prompts are re-run in 14-30 days with before/after screenshots and the next cycle queued.
One prompt, one city, across ChatGPT, Gemini & Perplexity. The real screenshot, emailed to you within a day.
Month one includes the baseline. The AI Ranking Program maps the market, weights the fixes, executes the plan, re-runs the same prompts, and proves movement.
Every AI Ranking Program starts with the AI Ranking + Reputation Defense Baseline: a metro/category market map across your locations, with the first priority-weighted execution plan and re-measurement window set for 14-30 days.
First proof in 14-30 days; 90-day minimum to expand, stabilize, and defend it.
The subscription is the program: measurement, priority-weighted AEO/local SEO/reputation work, re-measurement, and proof. Pricing is fixed for the scoped cycle; optional verified-lift success terms are defined only after baseline and proof thresholds are agreed.
Standalone baselines are reserved for diligence and strategy sprints and start at $7,500.
Show measurable movement in one priority market.
Become the AI recommendation in your core markets.
Defend category leadership across the full footprint.
Annual billing is the default: 2 months free, 90-day minimum, and volume location bands for larger footprints.
CitedLogic is built for competitive local brands, multi-location groups, franchises, and portfolio operators. If the market is valuable enough to justify a first-proof program, apply for a fit call.
Competitors ping AI from datacenters. We measure from real devices in your markets - the evidence layer that matches what your customer actually sees.
Location-controlled sessions on real phones and desktops in your customers' cities - not datacenter APIs.
Every finding ships with a timestamped screenshot and transcript. Audit-grade proof.
ChatGPT, Gemini & Perplexity + the Google map pack - measured across all of your locations.
Every published before/after passes a gate that reads the rank stamp from the screenshot itself - the pixels must match the claim, or it doesn't ship.
The baseline shows where each location ranks today, what AI says about your reputation, why competitors are being chosen, which category gaps matter first, and what weighted plan we will re-run in the first 14-30 day proof window.
Or start free - a one-prompt AI Ranking Snapshot, emailed in a day.