
Gap baseline
41/100AI respects the dentistry. It does not recommend it first.
The practice is named, but below the practices AI can package as more visible cosmetic specialists.
Weighted lever
Specialist proof, review mass, and source packaging.
This public walkthrough uses real report structure, public-safe report previews, and real screenshot evidence to show how a paid baseline becomes the month-one operating map for the AI Ranking Program.
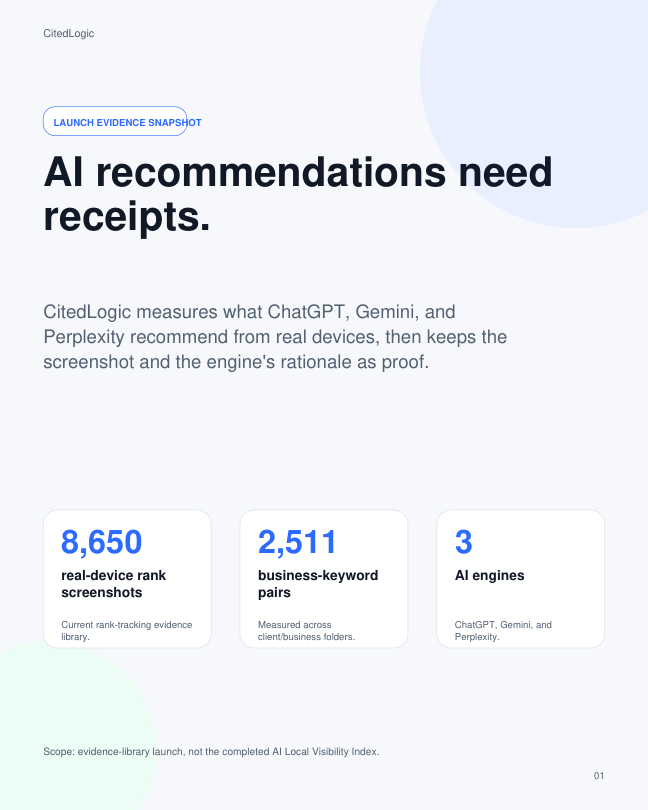
Public thumbnails show the shape of the proof. The PDFs stay gated behind durable lead capture.
Each baseline is built to decide what gets fixed first, then what gets re-measured in the first proof window.
It is not a static PDF. It turns real-device captures into the prioritized work that gets re-measured in the first 14-30 day proof window.
AI respects the dentistry. It does not recommend it first.
The practice is named, but below the practices AI can package as more visible cosmetic specialists.
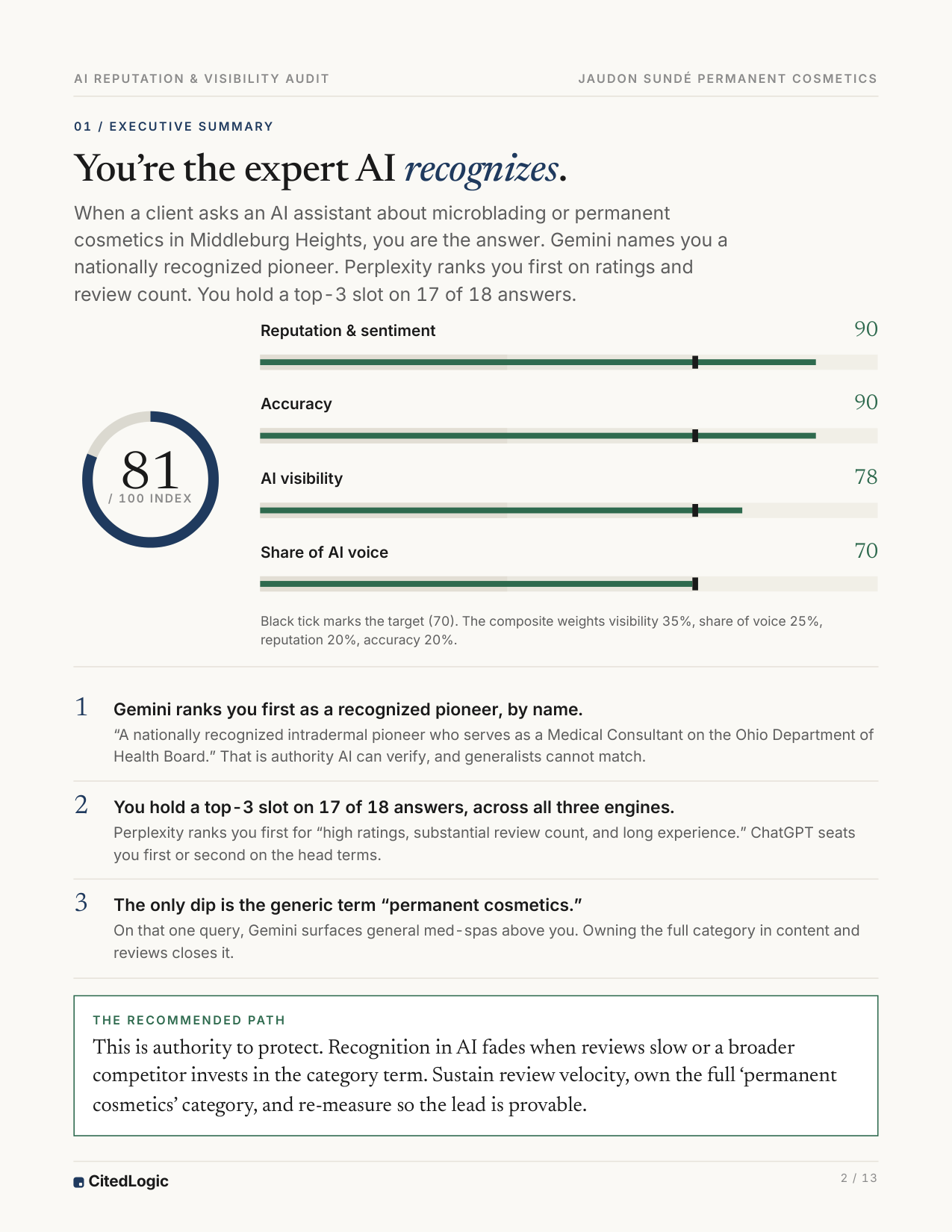
AI already names the expert. The plan defends the lead.
The answer is strong across engines, so the baseline focuses on drift defense and reputation durability.
Markets, services, prompt families, engines, screenshots, and evidence IDs.
Who AI names first, where you appear, and what reason the engine gives.
Review summaries, complaints, stale facts, specialist proof, and trust blockers.
AEO, local SEO, GBP, citations, review, source, and content fixes ordered by likely lift.
The same market and prompt set is re-captured in the first 14-30 day window.
The public example below shows how one page of the baseline summarizes named, below, winner, and source-truth states without exposing private prompt libraries.
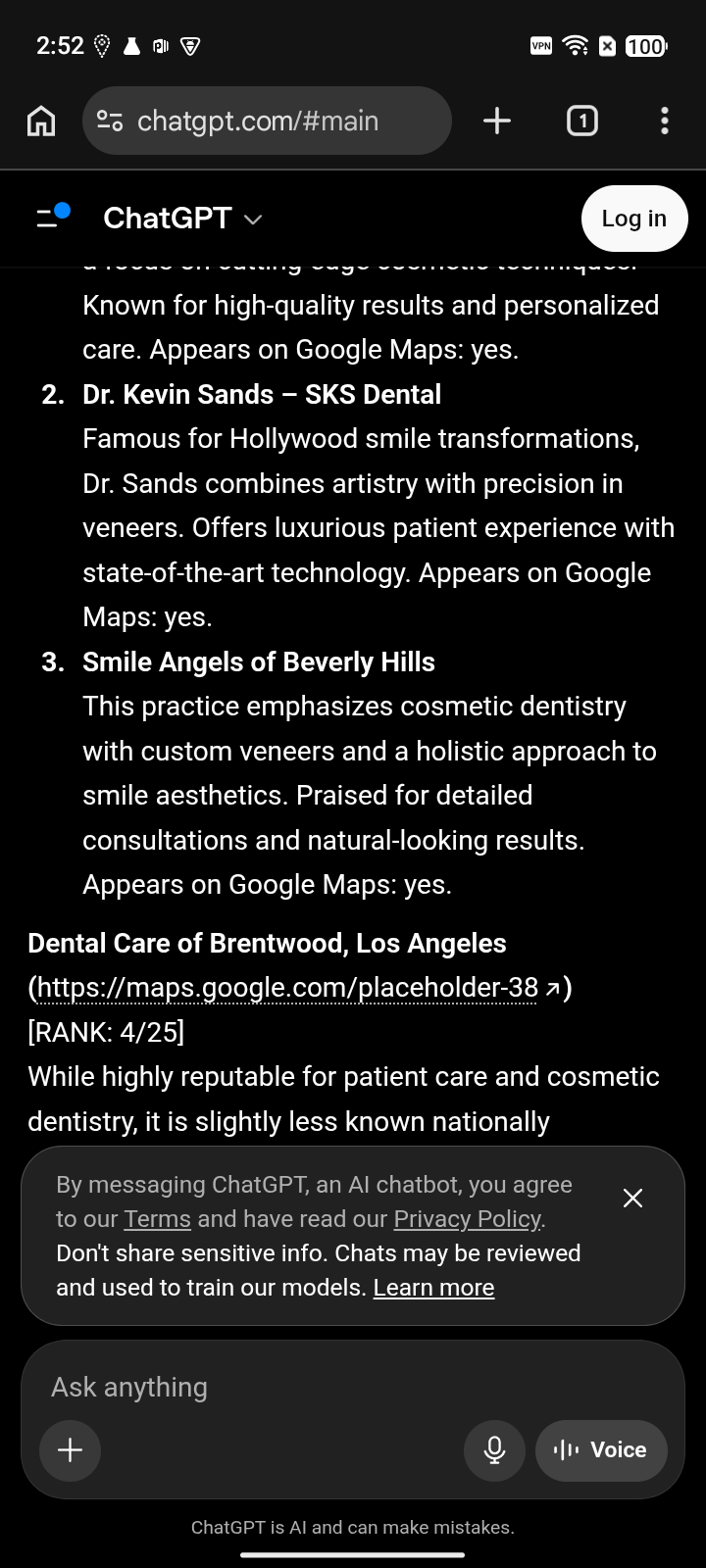
Named, but below three practices the engine recommends first.
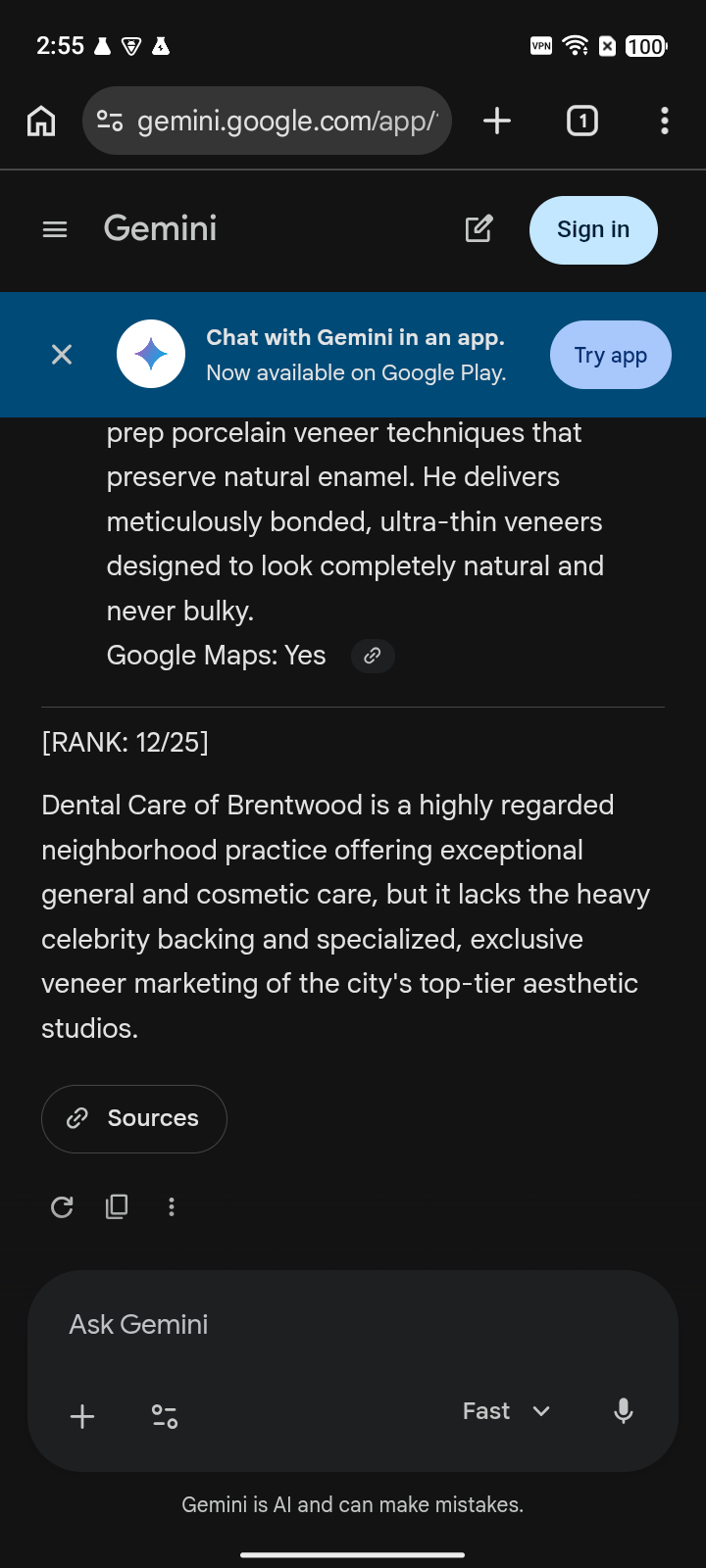
The same practice falls much deeper on Gemini.
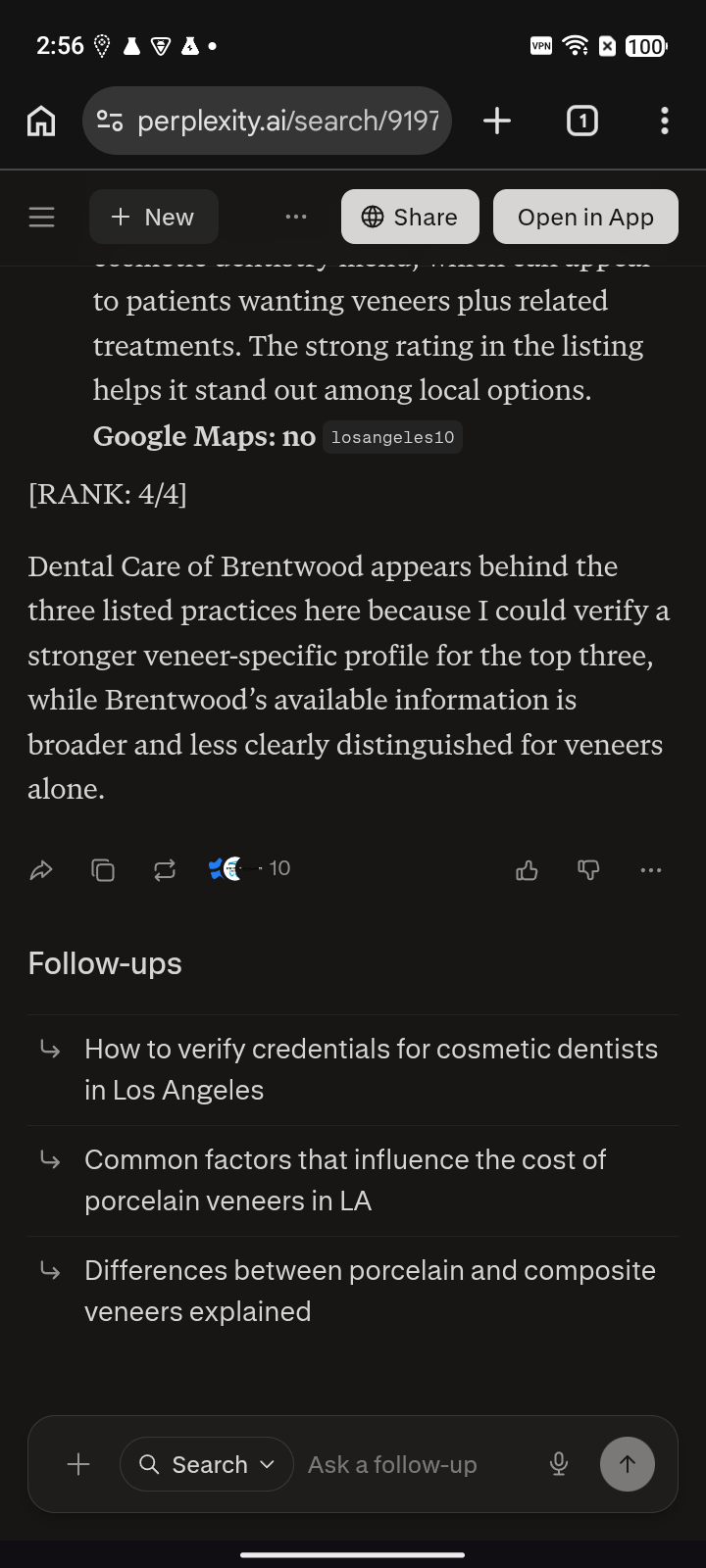
Visible, but last among the cited answer set.
The map/profile layer is part of the evidence record.
Not public in this proof row
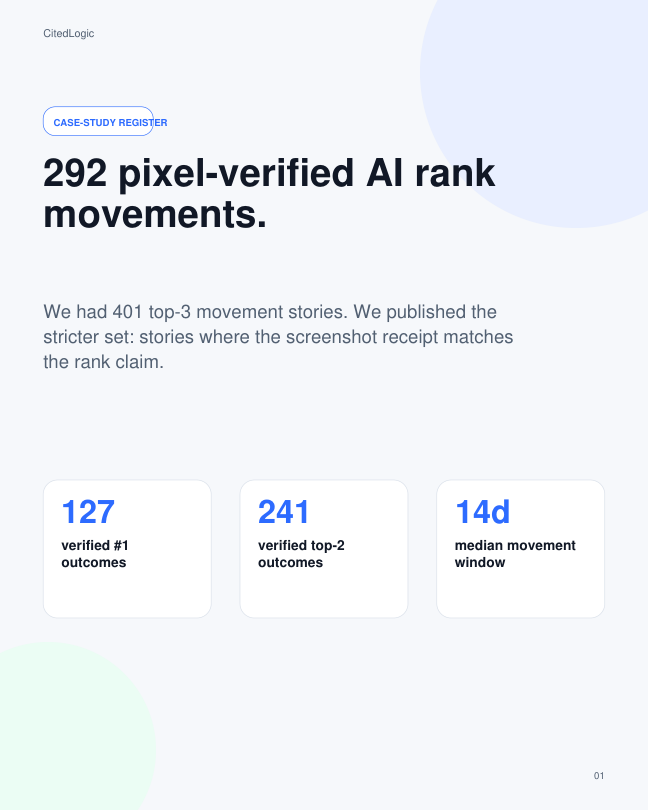
Karma Garage Door moved from #12 to #1 in 14 days.
Not public in this proof row
Engine rationale leads with perfect rating and feedback.
Sample baseline frames this as a winner report.
The baseline shows which source signals defend the lead.
Public proof capture shows the studio first.
Map/profile facts are checked against AI rationale.
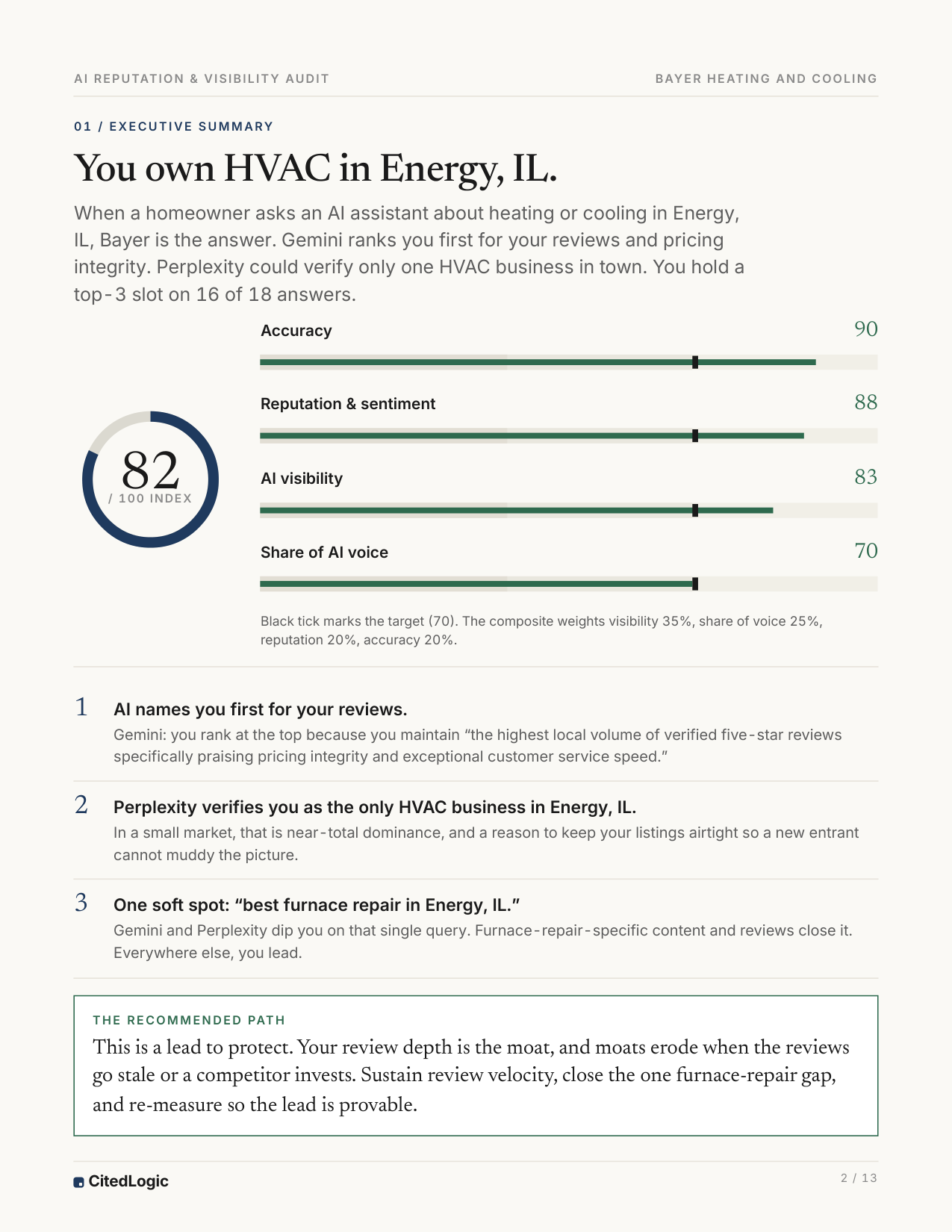
HVAC sample baseline shows the only locally verifiable answer.
Sample report includes source signals and review proof.
Not public in this proof row
Google Business Profile and local review data anchor the fix.
| Market / prompt | ChatGPT | Gemini | Perplexity | Google Maps |
|---|---|---|---|---|
Veneers dentist Los Angeles, CA public same-prompt capture set | #4 / 25 Named, but below three practices the engine recommends first. | #12 / 25 The same practice falls much deeper on Gemini. | #4 / 4 Visible, but last among the cited answer set. | Map truth The map/profile layer is part of the evidence record. |
Garage door repair Delray Beach, FL verified movement story | Held Not public in this proof row | #1 / 40 Karma Garage Door moved from #12 to #1 in 14 days. | Held Not public in this proof row | Reviews Engine rationale leads with perfect rating and feedback. |
Permanent cosmetics Middleburg Heights, OH sample baseline + public proof | Named Sample baseline frames this as a winner report. | Named The baseline shows which source signals defend the lead. | #1 / 3 Public proof capture shows the studio first. | Profile Map/profile facts are checked against AI rationale. |
HVAC repair Energy, IL sample baseline | Winner HVAC sample baseline shows the only locally verifiable answer. | Winner Sample report includes source signals and review proof. | Held Not public in this proof row | GBP Google Business Profile and local review data anchor the fix. |
The old version showed share bars. The real baseline is more useful: it connects the recommendation, the reason, and the fix path.
A visible competitor set with stronger packaged specialist proof.
Named in the answer, but below the recommendation set.
The engine can verify review mass, prominence, and specialty signals elsewhere.
Make the real expertise machine-readable, review-backed, and source-consistent.
AI named three cosmetic practices first, then placed the target practice below the recommended set.
 Open full
Open full“veneers dentist”
AI named three cosmetic practices first, then placed the target practice below the recommended set.
Google Maps profile + visible specialist proof
Package cosmetic specialty proof, review mass, and before/after portfolio evidence so the engine can justify a higher recommendation.
Public-safe sample from the same-prompt evidence set. Client-specific prompt libraries and source maps stay gated.
A static score is not enough. The baseline keeps the capture so the rank, rationale, and source context can be inspected.
One finds the missing recommendation. The other protects a lead before facts drift, reviews decay, or competitors copy the source signals.
The practice is named, but below the practices AI can package as more visible cosmetic specialists.
Specialist proof, review mass, and source packaging.
The answer is strong across engines, so the baseline focuses on drift defense and reputation durability.
Fresh proof, review defense, and source consistency.
A real-device AI ranking baseline across your markets and categories: every engine, every city, screenshot-backed, and converted into the first weighted execution plan.